希望这不是今年的唯一一篇Blog
Style Transfer
用神经网络做Style Transfer这个任务是Gatys等最先提出的。初代的Style Transfer需要随机初始化图片,把图片当做可以训练的变量,通过优化Content Loss和Style Loss来得到内容上与Content Image接近,风格上与Style Image接近的图像。这种形式属于固定风格固定内容的风格迁移
如何衡量生成图片与Content Image、Style Image的内容和风格的相似程度?首先是内容差异,将图像通过一个CNN(VGG),通过某一层输出的特征图来衡量图片的内容差异。风格差异是通过Gram矩阵来对风格进行数学表示,Gram矩阵实际上可看做是features之间的偏心协方差矩阵,将图片经过一个CNN(VGG),将其中的某(些)层 $l$ 的特征图 $F$,那么Gram矩阵可以表示为:
那么Content Loss就是输出和Content Image经过VGG后的某一层的Feature,Style Loss就是输出和Style Image经过VGG后Feature的Gram矩阵。
这种方法每一个Content-Style Pair都需要优化很长时间,Ulyanov等用一个神经网络替代优化的过程,也就是用了一个generator来生成,在这个generator里用了BN
然后他们又发现,把BN换成Instance Norm(IN)可以提升收敛速度,这俩的区别就在于BN是在一个Batch内统计的,而IN是单张图片统计的。
随后,Dumoulin等发现进行IN的时候,使用不同的 $\gamma$ 和 $\beta$ 就可以生成出不同风格的图像,一种风格对应一组 $(\gamma^i, \beta^i)$,于是就有了Conditional Instance Normalization
这种方法可以进行有限风格的迁移,每一个Style都需要训练一个新的模型。
在这个思想的基础上就有了Adaptive Instance Normalization也就是AdaIN,直接用一张图片算出 $\gamma$ 和 $\beta$,作用在另一张图像上,就可以实现任意风格的迁移。
Model
模型其实就很简单了,把Content和Style经过VGG后做AdaIN,最后通过一个Decoder来得到output。Decoder输出的结果再通过VGG来得到Content Loss和Style Loss
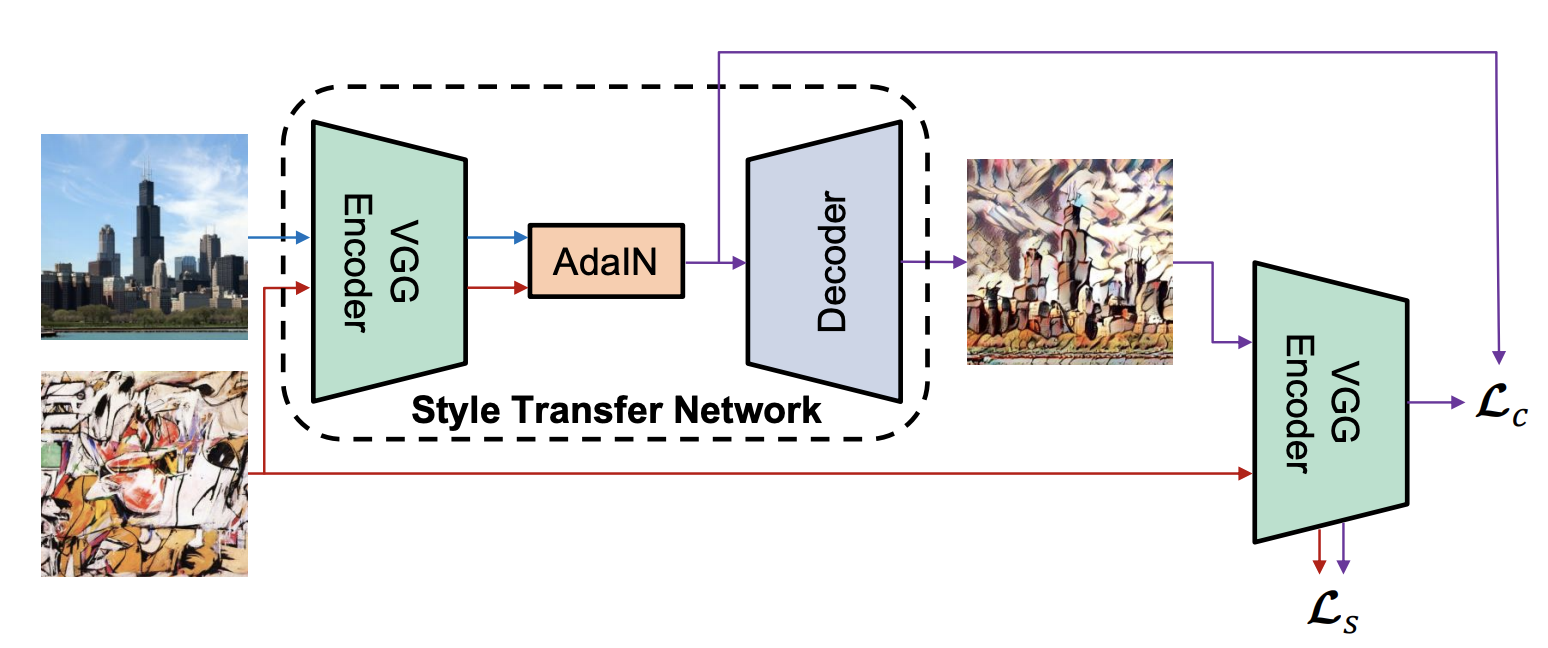
Content Loss还是常规的feature map的MSELoss,Style Loss这里变成了Decoder生成结果经过VGG后feature map的均值和方差做MSELoss,而不是Gram矩阵
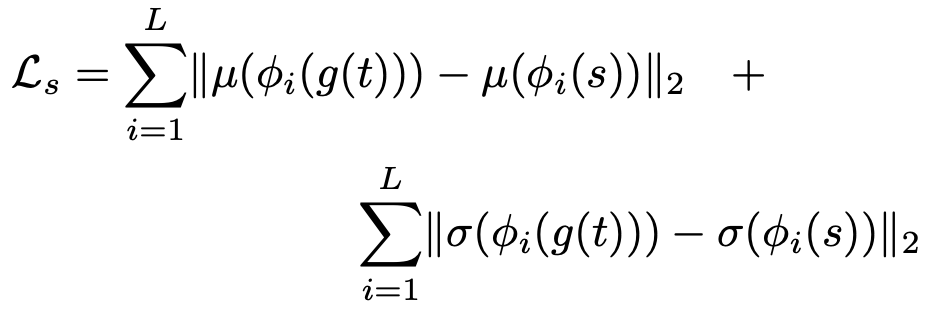
Training
训练就按照Paper上描述的,Content数据集用MS COCO,Style数据集用的WikiArt,COCO大概又11W张,WikiArt接近8W张。先resize到短边512,random crop到256训练,大概25个Epoch,Content Loss,Style Loss的weight和paper一致。
Results
直接上图
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

Style Interpolation
除了做Style Transfer之外,AdaIN还可以做Style Interpolation,把Style从弱到强过渡:
t = adain(content_features, style_features)
t = alpha * t + (1 - alpha) * content_features
out = Decoder(t)
放两张结果,从上到下从左到右分别为:Content Image, $\alpha=0.25$, $\alpha=0.5$, $\alpha=0.75$, $\alpha=1$, Style Image


Next
下篇争取国庆节妈的